معرفی VMware vCenter Server High Availability – قسمت اول
پلتفرم VMware vSphere یکی از پلتفرمهای مجازیسازی است که مبنایی برای ایجاد و مدیریت زیرساختهای مجازی برای Private Cloud و Public Cloud در سازمانها به شمار میرود. VMware vCenter Server Appliance یا به اختصار vCSA، در هسته اصلی vSphere قرار گرفته و سرویسهایی را برای مدیریت بخشهای مختلف در زیرساختهای مجازی مانند HostهایESXi ، ماشینهای مجازی، منابع شبکه و ذخیرهسازی ارائه مینماید. از آنجایی که زیرساختهای مجازی بزرگ با استفاده از vSphere ایجاد میشوند، vCenter Server به عنوان یکی از عوامل مهم در تضمین تداوم کسبوکار در یک سازمان محسوب میگردد.
vCenter Server باید خود را در مقابل مجموعهای از خرابیهای سختافزاری و نرمافزاری در محیط محافظت نموده و پس از بروز این خرابیها نیز به صورت Transparent بازیابی شود. vSphere 6.5 یک راهکار با دسترسپذیری بالا (HA) برای vCenter Server ارائه مینماید که تحت عنوان VMware vCenter Server High Availability یا به اختصار VCHA شناخته میشود.
بررسی معماری VMware vCenter Server High Availability
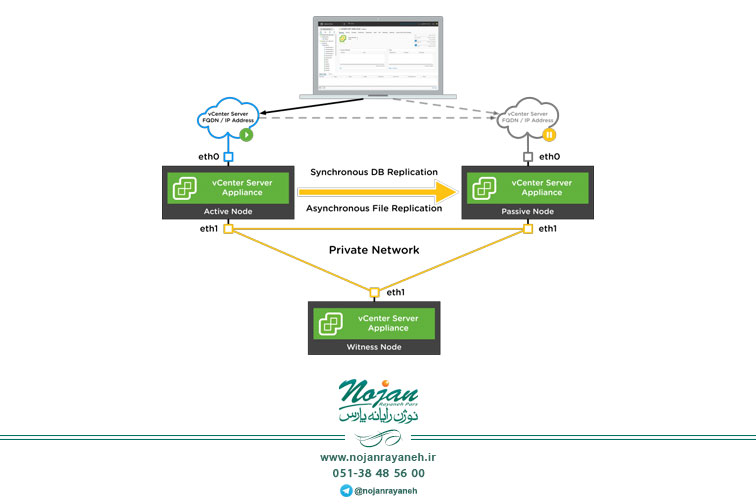
درمعماری vCenter High Availability از یک کلاستر دارای سهNode استفاده میشود تا قابلیت HA در برابر انواع مختلفی از مشکلات سختافزاری و نرمافزاری را ایجاد نماید. کلاستر vCenetr HA دارای یک Active Node جهت پاسخگویی به درخواستهای Client، یک Passive Node برای ارائه سرویس به جای Active Node در صورت بروز خرابی و یک Quorum Node تحت عنوانWitness میباشد. تمامی معماریهای مبتنی بر Node که در قالب Active یا Passive از فرآیند Failover به صورت اتوماتیک پشتیبانی مینماید، با اتکا بر موجودیت Tie Breaking یا Quorum به حل مشکل Split-Brain میپردازد؛ لازم به ذکر است مشکل Split-Brain به عدم هماهنگی و انطباق دادهها و قابلیت دسترسپذیری اطلاق میشود که میتواند به دلیل خرابی شبکه در سیستمهای توزیعی که دادههای Replicate شده را نگهداری میکنند، بروز نماید. در معماریهای قدیمی از انواع مختلف Shared Storage برای حل مشکل Split-Brain استفاده میشود اما در این طرح که با هدف پشتیبانی از یک کلاستر vCenter HA در چندین دیتاسنتر میباشد، پیادهسازی مبتنی بر Shared Storage مورد نظر قرار نمیگیرد.
در نتیجهی این طراحی همواره یک Node در کلاستر vCenter HA به عنوان Quorum Node یا Witness Node تعیین میگردد؛ همچنین دو Node دیگر با نقشهای Active و Passive در نظر گرفته میشوند.
دسترسپذیری یک vCenter Server تا زمانی تضمین میشود که دو Node فعال در داخل یک کلاستر وجود داشته باشد، اما در صورتی که فقط دو Node در کلاستر وجود داشته باشد، وضعیت کلاستر در حالت Degraded در نظر گرفته میشود و بروز خرابی بعدی در این کلاستر به معنای در دسترس نبودن سرویسهای vCenter خواهد بود.
vCenter Server Appliance به صورت Stateful بوده و برای عملکرد درست به یک حالت پایدار نیاز دارد. وضعیت Appliance (وضعیت پیکربندی یا زمان اجرا) عمدتا شامل موارد زیر میباشد:
ذخیره سازی دادههای پایگاه داده در دیتابیسی تحت عنوان PostgreSQL
فایلهای Flat مانند فایلهای پیکربندی
پشتیبانگیری از وضعیت Appliance به دلیل تاثیرگذاری در عملکرد صحیح VCHA Failover موضوعی مهم قلمداد میگردد. در شرایطی که ذخیرهسازی وضعیت در داخل پایگاهداده PostgreSQL انجام شود، از مکانیسم Replication که به صورت Native در PostgreSQL وجود دارد جهت همسانسازی دادهها در پایگاهداده اولیه و ثانویه استفاده میشود. به منظور همسانسازی فایلهای Flat نیز از یک راهکار Native لینوکسی با نام Rsync استفاده میگردد.
از آنجایی که vCenter Server Appliance نیاز به هماهنگی و سازگاری زیادی دارد، استفاده از روشهای Replication هماهنگ، جهت Replicate نمودن وضعیت Appliance از Active Node به Passive Node جزو ملزومات اساسی میباشد.
طراحی مناسب شبکه در این تکنولوژی باید ارتباطات مناسب (تاخیر کم و پهنای باند بالا) بین Nodeهای Active و Passive که تضمینکنندهی Recovery Point Objective یا به اختصار RPO با مقدار صفر میباشد را ارائه نماید.
کلاستر vCenter HA به شبکه مخصوص خود نیاز دارد که از شبکه مدیریتی برای vCenter Server Appliance جدا میباشد. همچنین باید سه FQDN یا IP استاتیک به هر یک از Nodeها اختصاص داده شود که برای ترافیک کلاستر VCHA در شبکه اختصاصی آن، مورد استفاده قرار میگیرند. Clientها میتوانند از طریق واسط کاربری مدیریتی شبکه که به صورت عمومی میباشد به سرور Active دسترسی یابند.
در ادامه به بررسی نقشهای هر یک از Nodeها در کلاستر vCenter HA میپردازیم:
بررسی Active Node:
Node اجرا کنندهی Active Instance مربوط به vCenter Server
دارای قابلیت ایجاد و استفاده از Public IP مربوط به کلاستر
بررسی Passive Node:
Node اجرا کنندهی Passive Instance مربوط به vCenter Server
دارای قابلیت دریافت به روزرسانیهای پیوسته مربوط به وضعیت Active Node در شرایط همزمان
همانند Active Node در رابطه با منابع
دارای قابلیت اجرای نقش Active Role در صورت بروز Failover
بررسی Witness Node:
دارای قابلیت عملکرد به عنوان Quorum Node
مورد استفاده برای قطع ارتباط در صورت بخشبندی شبکه و ایجاد موقعیتی که Nodeهای Active و Passive قادر به برقراری ارتباط با یکدیگر نباشند.
یک ماشین مجازی با استفاده از حداقل منابع سختافزاری و تصرف یک فضای محدود
عدم پذیرش نقش Nodeهای Active و Passive
در صورت بروز مشکل برای Active Node به هر دلیلی مانند مشکلات سختافزاری، نرمافزاری یا شبکهای، Passive Node نقش آن را به عهده گرفته و با استفاده از Public IP در نظر گرفته برای کلاستر فرآیند پاسخگویی به درخواستهای Client را آغاز مینماید.
در عین حال انتظار میرود که Clientها برای ادامه دسترسی به Appliance نیاز به Log On نمودن مجدد داشته باشند. از آنجایی که راهکارهای HA از فرآیند Replication همزمان پایگاهداده استفاده مینمایند، در طول Failover هیچ اطلاعاتی از بین نخواهد رفت که این موضوع به معنای صفر بودن RPO میباشد.
قابلیت دسترسپذیری vCenter Server Appliance در صورت بروز خرابی در هر یک از Nodeها مطابق با شرایط زیر عمل مینماید:
۱٫ خرابی Active Node
تا زمانی که ارتباط بین Passive Node و Witness Node برقرار باشد، Passive Node میتواند وضعیت خود را به حالت Active ارتقا داده و درخواستهای Client را پاسخ دهد.
- خرابی Passive Node:
تا زمانی که ارتباط بین Active Node و Witness Node برقرار باشد، Active Node میتواند به صورت فعال به اجرای نقش خود پرداخته و درخواستهای Client را پاسخ دهد.
- خرابی Witness Node:
تا زمانی که ارتباط بین Active Node و Passive Node برقرار باشد، Active Node همچنان فعالانه به اجرای نقش خود پرداخته و درخواستهای Client را پاسخ میدهد. ضمن اینکه Passive Node نیز به مراقبت از Active Node برای بروز Failover ادامه میدهد.
- خرابی بیش از یک Node یا جدا شدن Nodeها
این شرایط زمانی رخ میدهد که هر سه Node مربوطه یعنی Active, Passive و Witness قادر به برقراری ارتباط با یکدیگر نباشند. این حالت مربوط به زمانی است که خرابی در بیش از یک نقطه روی میدهد و در این صورت کلاستر غیرکاربردی فرض شده و قابلیت دسترسپذیری آن نیز تحت تاثیر قرار میگیرد زیرا VCHA برای پاسخگویی در شرایط بروز مشکل برای بیش از یک Node طراحی نشده است.
- رفتار مجزای Nodeها
در صورت جدا شدن یک Node از کلاستر، این Node به صورت خودکار از کلاستر خارج شده و تمام سرویسها متوقف میشوند. به عنوان مثال، در صورت جدا شدن Active Node، تمامی سرویسها به منظور تضمین این موضوع که آیا Passive Node در صورت حفظ ارتباط باWitness Node قادر به پذیرش مسئولیت میباشد یا خیر، متوقف میشوند.
ناکارآمدیهای متناوب شبکه در فرآیند شناسایی Node جدا شده، مورد توجه قرار گرفته و پس از به نتیجه نرسیدن تمامی تلاشها در یک حالت مجزا قرار میگیرد.
تعامل Client و Failover
Clientها برای ارتباط با vCenter Server Appliance از IP Public استفاده مینماید. در صورتی که Failover رخ دهد، Passive Node مسئولیت Active Node دچار مشکل شده را که دارندهی Public IP نیز بوده بر عهده خواهد گرفت.
میزان Recovery Time Objective یا RTO در این راهکار چند دقیقه میباشد که در طول این مدت Client باید برای اختلالهای پیش آمده آمادگی داشته باشد.
در قسمت دوم (پایانی) از سری مقالههای HA در VMware vCenter به بررسی ویژگیهای این تکنولوژی و برخی تنظیمات آن خواهیم پرداخت.
ــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــ